0x01 什么是业务线程池
Question:无论是那种类型的 Reactor 模型,都需要在 Reactor 所在的线程中,进行读写操作。那么此时就会有一个问题,如果我们读取到数据,需要进行业务逻辑处理,并且这个业务逻辑需要对数据库、缓存等等进行操作,会有什么问题呢?假设这个数据库操作需要 5 ms ,那就意味着这个 Reactor 线程在这 5 ms 无法进行注册在这个 Reactor 的 Channel 进行读写操作。也就是说,多个 Channel 的所有读写操作都变成了串行。势必,这样的效率会非常非常非常的低。
解决:那么怎么解决呢?创建业务线程池,将读取到的数据,提交到业务线程池中进行处理。这样,Reactor 的 Channel 就不会被阻塞,而 Channel 的所有读写操作都变成了并行了。
案例: 《Dubbo 用户指南 —— 线程模型》就是使用线程池来处理IO线程中时间处理逻辑较慢 or 需要发起新请求的情况(查询数据库、连接事件中发起登陆请求.etc)
0x02 TCP粘包、拆包问题
TCP是以流的方式来处理数据,所以会导致粘包 / 拆包。
- 拆包:一个完整的包可能会被 TCP 拆分成多个包进行发送。
- 粘包:也可能把小的封装成一个大的数据包发送。
原因
应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象。而应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包现象。
待发送数据大于 MSS(最大报文长度),TCP 在传输前将进行拆包。
- 以太网帧的 payload(净荷)大于 MTU(默认为 1500 字节)进行 IP 分片拆包。
- 接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
解决方案
在 Netty 中,提供了多个 Decoder 解析类,如下:
- ① FixedLengthFrameDecoder ,基于固定长度消息进行粘包拆包处理的。
- ② LengthFieldBasedFrameDecoder ,基于消息头指定消息长度进行粘包拆包处理的。
- ③ LineBasedFrameDecoder ,基于换行来进行消息粘包拆包处理的。
- ④ DelimiterBasedFrameDecoder ,基于指定消息边界方式进行粘包拆包处理的。
实际上,上述四个 FrameDecoder 实现可以进行规整:
- ① 是 ② 的特例,固定长度是消息头指定消息长度的一种形式。
- ③ 是 ④ 的特例,换行是于指定消息边界方式的一种形式。
0x03 Netty 零拷贝实现
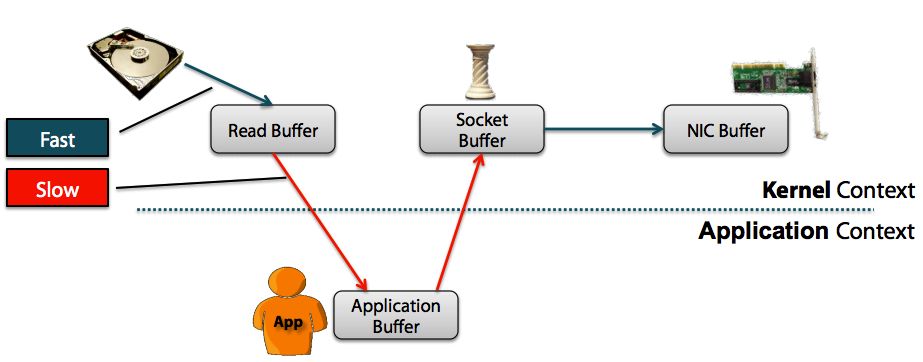
WIKI中指出“零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
Non-Zero Copy
Zero Copy
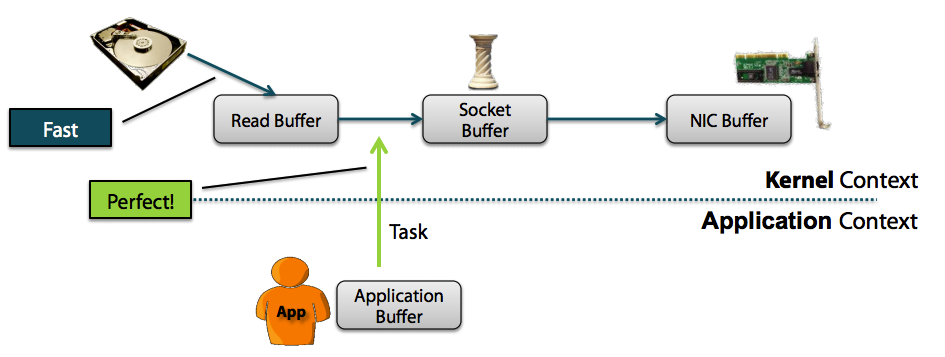
上图中可以清楚的看到,Zero Copy的模式中,避免了数据在用户空间和内存空间之间的拷贝,从而提高了系统的整体性能。Linux中的sendfile()以及Java NIO中的FileChannel.transferTo()方法都实现了零拷贝的功能,而在Netty中也通过在FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝。
1.【重点】Netty 的接收和发送 ByteBuffer 采用堆外直接内存 Direct Buffer
- 使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝;使用堆内内存会多了一次内存拷贝,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。
- Netty 创建的 ByteBuffer 类型,由 ChannelConfig 配置。而 ChannelConfig 配置的 ByteBufAllocator 默认创建 Direct Buffer 类型。
2.CompositeByteBuf 类,可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf ,避免了传统通过内存拷贝的方式将几个小 Buffer 合并成一个大的 Buffer 。
- addComponents(…) 方法,可将 header 与 body 合并为一个逻辑上的 ByteBuf 。这两个 ByteBuf 在CompositeByteBuf 内部都是单独存在的,即 CompositeByteBuf 只是逻辑上是一个整体。
3.通过 FileRegion包装的FileChannel
- tranferTo(…)` 方法,实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel ,避免了传统通过循环 write 方式,导致的内存拷贝问题。
- Netty的wrap 方法
- 我们可以将
byte[]数组、ByteBuf、ByteBuffer 等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作。
0x04 Netty 随处可见的InEventLoop()的作用
这个是判断当前线程是否在事件循环线程中,因为为了保证一个Channel上的事件处理的线程安全,要把所有的IO事件等使用IO线程来处理,就需要判断当前线程是否是eventLoop线程,如果是则可以直接执行,否则需要提交给eventLoop线程去执行。
1 | public boolean inEventLoop() { |
inEventLoop(Thread)方法是EventExecutor中定义的抽象方法中,NioEventLoop继承的SingleThreadEventExecutor的实现是直接比较自己的线程,因为SingleThread只有一个线程。
1 | public boolean inEventLoop(Thread thread) { |
0x05 原生NIO存在的Epoll Bug 是什么? Netty的解决方案(重要)
1 什么是Epoll 空轮训
Java原生NIO编写服务器应用代码大体如下:
1 | // 创建、配置 ServerSocketChannel |
selector.select() 应该 一直阻塞,直到有就绪事件到达,但很遗憾,由于 Java NIO 实现上存在 bug,select() 可能在 没有 任何就绪事件的情况下返回,从而导致 while(true) 被不断执行,最后导致某个 CPU 核心的利用率飙升到 100%,这就是臭名昭著的 Java NIO 的 epoll bug。
实际上,这是 Linux 系统下 poll/epoll 实现导致的 bug,但 Java NIO 并未完善处理它,所以也可以说是 Java NIO 的 bug。
该问题最早在 Java 6 发现,随后很多版本声称解决了该问题,但实际上只是降低了该 bug 的出现频率,起码从网上搜索看,Java 8 还是存在该问题(当 Thrift 遇到 JDK Epoll Bug)。
2. Netty 的解决之道
很多 NIO 框架都在 Java 原生 NIO 基础上增加了解决 epoll 空轮询的增强,本文介绍 Netty 的做法。
Netty 的解决方式分为两步:
- 检测 epoll bug;
- 通过重建
Selector解决 epoll bug;
其实大部分框架的解决方式都类似,差别仅在 检测方式,检测到后基本都是通过重建 Selector 来解决。
Netty检测epoll空轮训的方式
Netty 使用 NioEventLoop.select() 替代 Selector.select(),检测 epoll bug 的逻辑就在 NioEventLoop.select() 中:
1 | selectCnt = 0; // epoll 空轮询场景下 select 调用次数 |
如果满足以下两个条件,则认为发生 epoll 空轮询:
selector.select(timeoutMillis)阻塞时间小于timeoutMillis,且select执行次数 > 阈值(默认 512)
因为阻塞时间无法做到很精准,所以若某次阻塞时间大于等于 timeoutMillis 立刻重置 selectCnt 为 1,即需要 连续 512 次 selector.select(timeoutMillis) 阻塞时间都小于 timeoutMillis 才认为发生了 epoll 空轮询。
timeoutMillis 有一套计算逻辑,无法进行配置,而次数阈值可以通过 io.netty.selectorAutoRebuildThreshold 系统配置进行设置,默认值为 512。
解决epoll空轮训
通过重建selector来变相实现解决epoll空轮训,具体的实现方式可以参考Java NIO epoll bug 以及 Netty 的解决之道,大体的思路如下:
- 新建一个
Selector; - 将旧
Selector的所有 channel 注册到新Selector上; - 关闭旧
Selector;
检测到 epoll bug 后,通过 selectRebuildSelector 方法来实际解决:
1 | private Selector selectRebuildSelector(int selectCnt) throws IOException { |
重建过程代理给了 rebuildSelector 方法,重建完成后,立即 selectNow 重新监听事件。
而 rebuildSelector 又把重建逻辑代理给了 rebuildSelector0:
1 | /** |
rebuildSelector()方法重新打开一个Selector;然后遍历oldSelector,将所有的key重新注册到新的Selector;然后重新赋值selector,selectCnt = 1;这时候已经规避了空轮询。
⚠️这里我们注意到了有一个关于InEventLoop(Thread) 的判断,参考一下0x04的介绍。在 Netty 中,一个 IO 线程可以处理多个 channel,但一个 channel 只能被一个 IO 线程处理,重建 Selector 必须 在事件循环线程内完成,如果当前线程是 NioEventLoop 线程,则直接在当前线程执行 Selector 重建,否则将重建任务 submit 给各个 NioEventLoop。
添加该判断的原因是除了 NioEventLoop 检测到 epoll bug 时会调用 rebuildSelector 外,NioEventLoopGroup 也有调用:
1 | public void rebuildSelectors() { |
0x06 Netty 空闲检测
在 Netty 中,提供了 IdleStateHandler 类,正如其名,空闲状态处理器,用于检测连接的读写是否处于空闲状态。如果是,则会触发 IdleStateEvent 。
IdleStateHandler 目前提供三种类型的心跳检测,通过构造方法来设置。代码如下:
1 | // IdleStateHandler.java |
readerIdleTimeSeconds参数:为读超时时间,即测试端一定时间内未接受到被测试端消息。writerIdleTimeSeconds参数:为写超时时间,即测试端一定时间内向被测试端发送消息。allIdleTimeSeconds参数:为读或写超时时间。
0x07 Netty ByteBuf 的优势
是对原生NIO ByteBuffer的一次全面升级
- A01. 它可以被用户自定义的缓冲区类型扩展
- A02. 通过内置的符合缓冲区类型实现了透明的零拷贝
- A03. 容量可以按需增长
- A04. 在读和写这两种模式之间切换不需要调用
#flip()方法- A05. 读和写使用了不同的索引
- A06. 支持方法的链式调用
- A07. 支持引用计数
- A08. 支持池化
0x08 Netty 内存管理
todo
0x09 Netty 内存泄露检测
todo
0x10 Netty 发送消息有几种方式
ctx.channel().writeAndFlush()
直接写入 Channel 中,消息从 ChannelPipeline 当中尾部开始移动;
ctx.writeAndFl ush()
写入和 ChannelHandler 绑定的 ChannelHandlerContext 中,消息从 ChannelPipeline 中的下一个 ChannelHandler 中移动。
0x11 默认情况 Netty 起多少线程?何时启动?
Netty 默认是CPU处理器数的两倍,bind后启动
0x12 同步与异步、阻塞与非阻塞的区别?
同步:
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做,等前一件做完了才能做下一件事。
例如普通B/S模式(同步):提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事
异步:
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
例如 ajax请求(异步): 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
阻塞:
阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。
有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回,它还会抢占cpu去执行其他逻辑,也会主动检测io是否准备好。
非阻塞
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
总结来说,在 Unix IO 模型的语境下:
- 同步和异步的区别:数据拷贝阶段是否需要完全由操作系统处理。
- 阻塞和非阻塞操作:是针对发起 IO 请求操作后,是否有立刻返回一个标志信息而不让请求线程等待。
0x13 什么是网络IO模型
linux 的IO模型大体有如下几种:
01 Blocking I/O(阻塞I/O)
这是最基础的I/O模型,也有人会叫它「同步阻塞I/O」,如下图(从网卡读取UDP数据)所示,请求数据的进程需要一直阻塞等待读取完成才能返回,同时整个读取的动作(这里是recvfrom)也是要同步等待I/O操作的完成才返回。
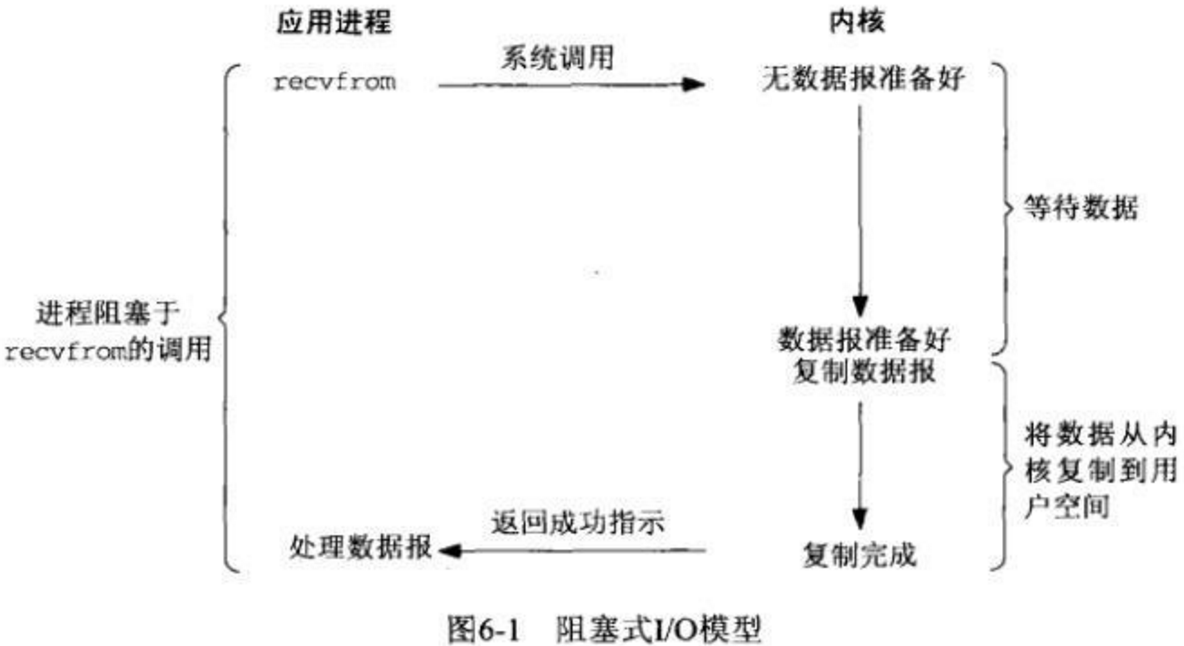
当用户进程调用了recv()/recvfrom()这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。第二个阶段:当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来
blocking IO的特点就是在IO执行的两个阶段都被block了。
02 同步非阻塞 IO(nonblocking IO)
同步非阻塞就是 “每隔一会儿瞄一眼进度条” 的轮询(polling)方式。它与BIO刚好相反,当数据没有准备好的时候,recvfrom调用仍然是同步返回结果,只是如果I/O不可用,它会即时返回一个错误结果,然后用户进程不断轮训,那么对于整个用户进程而言,它是非阻塞的。通常情况下,这是一种低效且十分浪费CPU的操作。
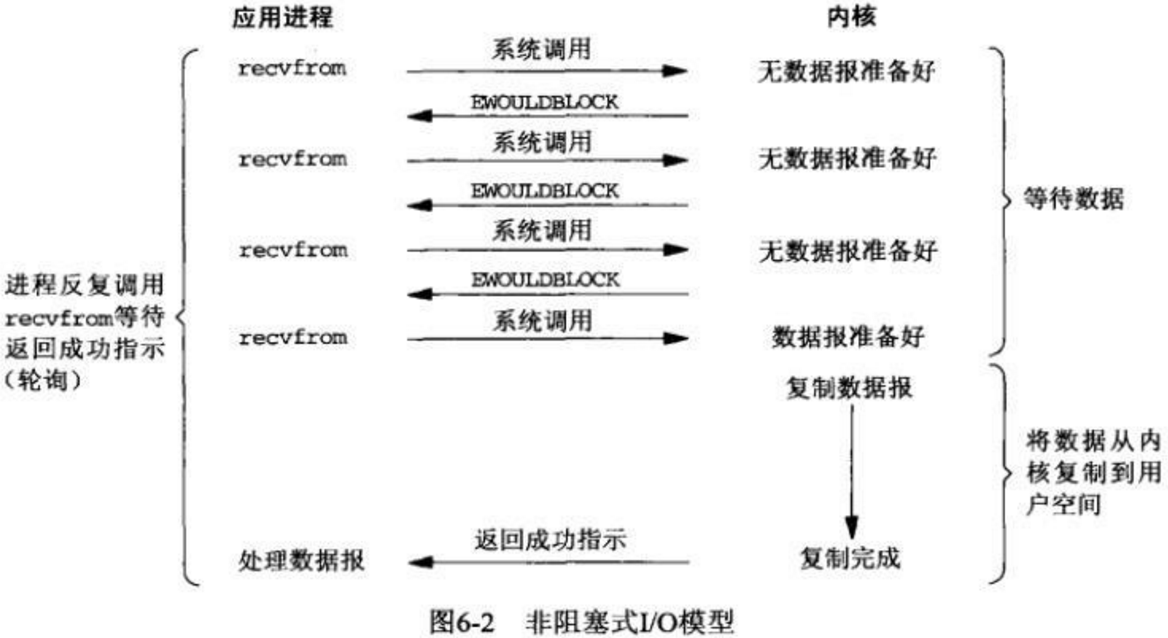
NIO的特点是用户进程需要不断主动询问kernel数据好了没有
优点:能够在等待任务完成的时间执行其他活(后台可以多个任务同时执行)
缺点:任务完成响应的延迟增大
03 IO 多路复用(IO Multiplexing)
如下图所示,在调用recvfrom之前先调用另外一个系统调用select,当它返回时就表示我们的数据准备好了,然后再调用recvfrom就能直接读取到数据了。在这种场景下,整个读取的动作(由两个系统调用组成)是异步的,同时select动作是会一直阻塞等待I/O事件的到来。
这种模式有个优点,这里的select往往可以监听很多事件,它往往是在多线程的场景下使用,比如在Java的NIO编程中,多个线程可以向同一个Selector注册多个事件,这样就达到了多路复用的效果。
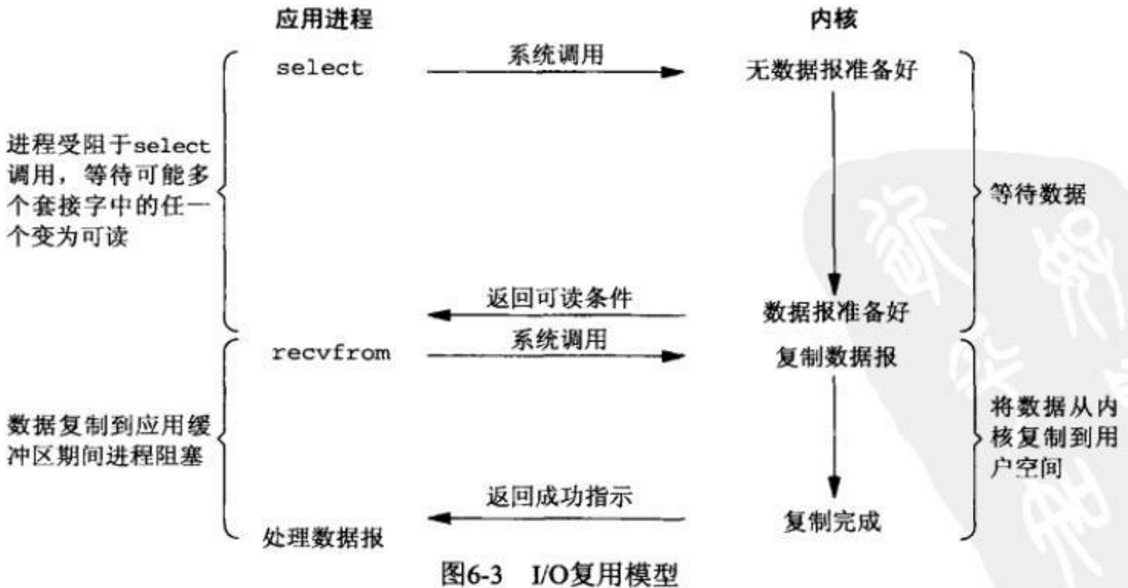
IO多路复用在阻塞到select阶段时,用户进程是主动等待并调用select函数获取数据就绪状态消息,并且其进程状态为阻塞。所以,把IO多路复用归为同步阻塞模式。
04 信号驱动IO(Signal-Driven IO)
信号驱动式I/O:首先我们允许Socket进行信号驱动IO,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。过程如下图所示
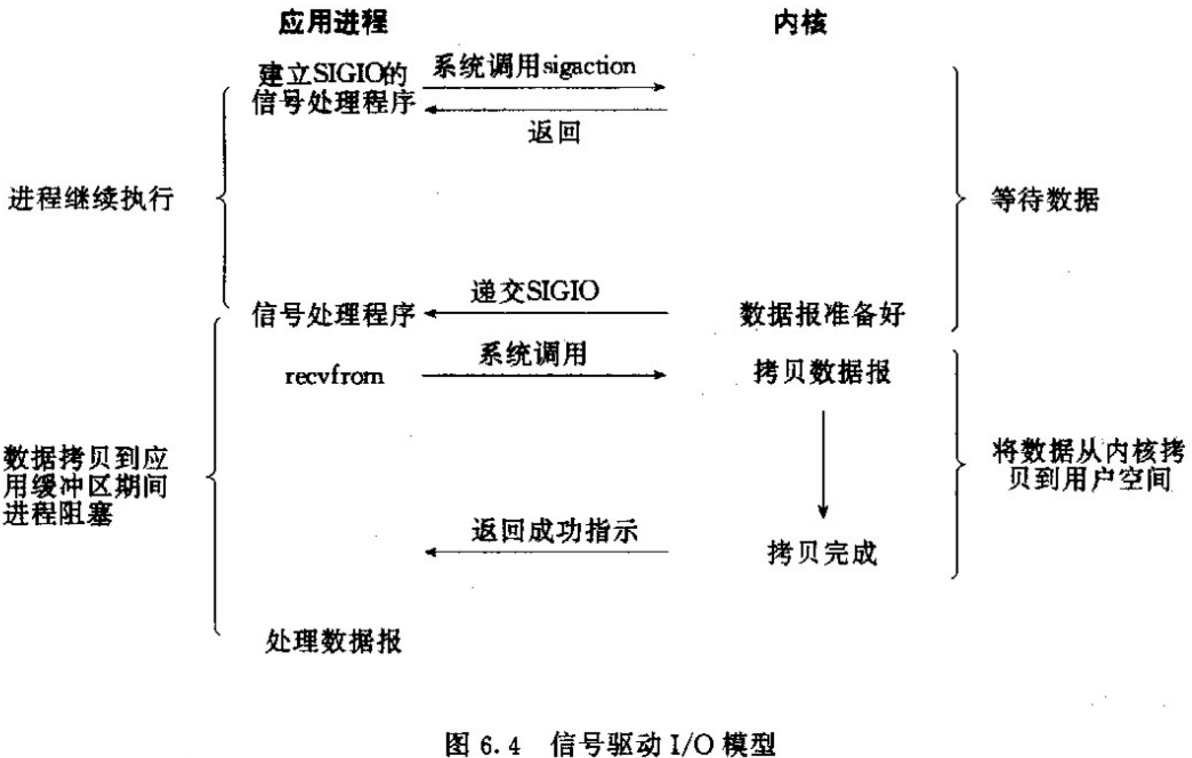
05 异步非阻塞IO(asynchronous IO)
相对于同步IO,异步IO不是顺序执行。用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程,然后用户态进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知。IO两个阶段,进程都是非阻塞的。
用户进程发起aio_read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal或执行一个基于线程的回调函数来完成这次 IO 处理过程,告诉它read操作完成了。
0x13 BIO、AIO与NIO的区别
- Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
- Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
- Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
0x14 select、poll、epoll的机制及其区别?
select模型:说的通俗一点就是各个客户端连接的文件描述符也就是套接字,都被放到了一个集合中,调用select函数之后会一直监视这些文件描述符中有哪些可读,如果有可读的描述符那么我们的工作进程就去读取资源。
poll模型:poll 和 select 的实现非常类似,本质上的区别就是存放 fd 集合的数据结构不一样。select 在一个进程内可以维持最多 1024 个连接,poll 在此基础上做了加强,可以维持任意数量的连接。
Epoll模型:epoll 是 select 和 poll 的增强版,epoll 同 poll 一样,文件描述符数量无限制。epoll是基于内核的反射机制,在有活跃的 socket 时,系统会调用我们提前设置的回调函数。而 poll 和 select 都是遍历。
三者的区别:select 和 poll 方式有一个很大的问题就是,我们不难看出来 select 是通过轮训的方式来查找是否可读或者可写,打个比方,如果同时有100万个连接都没有断开,而只有一个客户端发送了数据,所以这里它还是需要循环这么多次,造成资源浪费。而Epoll使用基于内核的反射机制,在有活跃的 socket 时,系统会调用我们提前设置的回调函数,避免了循环操作。
Epoll的缺点:**但是也并不是所有情况下 epoll 都比 select/poll 好,比如在如下场景:
在大多数客户端都很活跃的情况下,系统会把所有的回调函数都唤醒,所以会导致负载较高。既然要处理这么多的连接,那倒不如 select 遍历简单有效。
0x15 Netty 组件有哪些,分别有什么关联
参考Netty面试题整理二)
0x16 Netty 执行流程
01 服务端


1、创建ServerBootStrap实例
2、设置并绑定Reactor线程池:EventLoopGroup,EventLoop就是处理所有注册到本线程的Selector上面的Channel
3、设置并绑定服务端的channel
4、5、创建处理网络事件的ChannelPipeline和handler,网络时间以流的形式在其中流转,handler完成多数的功能定制:比如编解码 SSl安全认证
6、绑定并启动监听端口
7、当轮训到准备就绪的channel后,由Reactor线程:NioEventLoop执行pipline中的方法,最终调度并执行channelHandler
02 客户端


参考:
- Java NIO epoll bug 以及 Netty 的解决之道
- Netty 面试题
- 聊聊Linux 五种IO模型
- select、poll、epoll之间的区别(搜狗面试)
- 彻底理解Netty—–内部执行流程

- 本文作者: Noisy
- 本文链接: http://Metatronxl.github.io/2019/10/22/Netty-面试题整理-三/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!